What is a P2P Network? Peer-to-Peer Networks
There are many ways to classify a blockchain. One of them is to determine if the blockchain is public or permissioned. Permissioned blockchains are meant for defined groups of people, such as a consortium of companies that want to share a consistent database.
Public blockchains are commodities, digital goods that anyone with an internet connection can access. Nobody owns these commodities, so there is no central infrastructure provider. Instead, the infrastructure is provided by many independent peers, spread all over the globe.
The distributed Peer-to-Peer (P2P) network of a decentralized blockchain is highly resilient because the network’s nodes run independently from one another.
We’ll focus on the protocol of a blockchain at the network layer. At the network layer, peers are identified by their IP addresses.
It handles the communication between nodes via inter-node TCP connections - read: the internet.
It is desirable to keep IP addresses and public keys unlinkable for privacy reasons.
What is a Peer-to-Peer Network?
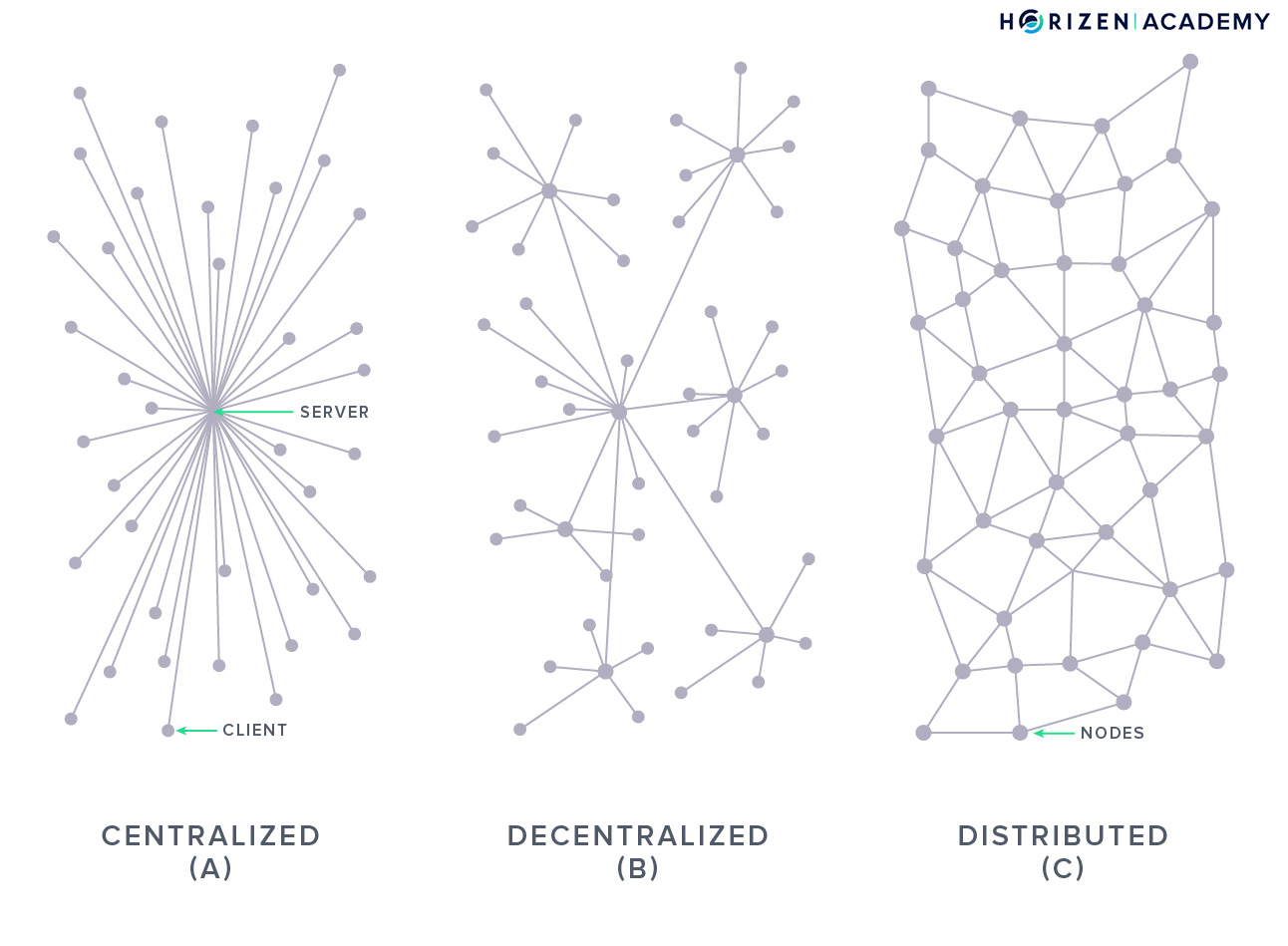
In a peer-to-peer network (P2P), every participant plays the same role; they are all peers. Each peer is both a client - requesting data, and a server - providing data.
When you compare it to a regular website, this makes it a lot more robust.
A special computer on the internet stores most websites. This special computer is commonly known as a server. If you want to access the website, you connect directly to the server.
If this computer happens to have a problem, the website won’t work. With a P2P network on the other hand, if one machine becomes unavailable, the remaining machines continue to provide services.
In a P2P network, you are usually connected to several peers and if one goes offline, everything still works as usual. This makes blockchain networks very robust.

Peer-to-Peer Networks
The Internet that we are experiencing today is highly centralized. Most data that we as the users of the internet produce, end up in the hands of a few large corporations. But there are a number of truly distributed systems out there living on the internet.
One example of a truly distributed system on the internet is BitTorrent.
Like any other technology, Peer-to-Peer networks have enabled legitimate use-cases, such as the reliable exchange of open-source software as well as illegitimate use-cases, such as pirating music and movies.
Advantages to P2P Networks
Distributed systems have some major advantages over their more centralized counterparts, most notably their robustness.
Peer-to-Peer networks have a high level of redundancy built-in. Single points of failure are missing and the system can survive even if a majority of the network is shut down.
We’ve seen the tremendous difficulty that authorities have had taking some of these networks offline with services like BitTorrent or Napster.
That is due to the fault tolerance you get from a peer-to-peer architecture.
But there are some downsides compared to centralized systems. The high level of redundancy and the need for communication, as well as coordination between peers, comes at the cost of efficiency.
Taking a look at data storage is the most obvious example here.
Many nodes, in the case of the Horizen network, more than 35,000, store a copy of the blockchain. This is not very storage efficient but makes the blockchain highly resilient against attacks and gives it its immutability.
In computer science, the CAP theorem describes the cost of a robust and scalable distributed network as the time it takes for the network to reach consistency. It takes some time for an event, like a transaction, to be broadcast to every node on the network.
In a second step, all the nodes have to reach consensus on the order in which events happened.
We have found a simple yet great visualization of a distributed system that demonstrates the process of new peers joining a network and syncing with all other nodes. It lets you add and delete random nodes to show the robustness of the overall system.
With a Peer-to-Peer network architecture, every node is equal to every other node. Every node in a P2P network acts as both a client and a server opposed to traditional client-server models.
While a server can experience downtimes during which the clients cannot access its data, in a P2P network you just connect to a different peer if one goes offline.
The Purpose of P2P Networks
Note: When we use the term nodes in this article, we refer to full nodes storing a copy of the entire blockchain.
We will use the term light nodes whenever we explicitly talk about them.
Light nodes don’t store a copy of the blockchain, rather only a key pair. They do not verify other transactions or blocks and need to connect to a full node before they can interact with the blockchain.
They are basically clients that connect to one of the full nodes that act as a server.
First and foremost, the P2P network facilitates the communication between nodes. Data on a blockchain is secure because many copies exist. Those copies need to be in sync, otherwise having a large number of copies would not make much sense.
In order for all nodes to stay in sync, they need to communicate constantly to update each other on events, such as new transactions or blocks.
The communication between nodes happens via TCP, a key part of the internet protocol suite at the transport layer.
Additionally, the communication between nodes can be secured using TLS, a cryptographic protocol at the application layer to provide private and secure communication.
The communication between Secure Nodes and Super Nodes on the Horizen blockchain is secured using TLS.
A P2P network protocol should ensure that querying a small fraction of nodes (e.g. logarithmic to the total node count) is enough to find information stored on a subset of all nodes. The situation with blockchains is slightly different.
All nodes store a copy of the blockchain.
This is the second major purpose of the P2P network: maintaining a large number of independent copies of the same data.
Because every node stores a copy of the blockchain, peer discovery is more important than content discovery in terms of optimizing the network protocol.
Properties of P2P Networks
When you put yourself into the position of someone wanting to launch a distributed system, like a blockchain, running it on a P2P network is the obvious choice for at least two reasons:
- First, it doesn’t require many resources to bootstrap. The P2P network can be spun up with only a handful of nodes at near zero cost. Once the network gains traction, new nodes can be added seamlessly.
- Second, it provides a high level of resilience. The more people join the network, the more resilient it becomes. One of the stated goals of Bitcoin is to be able to withstand state-level actors trying to attack the network. In the very beginning, when there were only a few nodes, this was not the case.
However, at the same time, the incentives for potential attackers to target the network were small. As more people joined the network, the network’s value increased, and so did the incentives to target the network.
Unfortunately for the attackers, Bitcoin’s growth also increased its resilience. You could say the robustness of a P2P network scales with the incentives to actually perform an attack.
A similar development could be observed with the BitTorrent protocol used for P2P file sharing. Although the entertainment industry wanted to shut it down, all attempts failed.
The two aforementioned reasons for using P2P networks to run public blockchains are compelling, but distributed systems do come with trade-offs.
While security benefits from the redundancy of information, this comes at a performance cost. In order to achieve a high level of decentralization, the minimal requirements to run a node should not pose a high barrier to entry.
This, in turn, means that the least performant nodes (in terms of bandwidth and/or computational power) limit the network as a whole.
The Network Graph
To illustrate distributed networks we use graphs.
This term sounds very simple at first but there is a bit more to it. The field of graph theory is a mathematical discipline studying the different types of graphs. We touch on graph theory in an article on Directed Acyclic Graphs or DAGs.
There, we talked about graphs in the context of data structures - namely how blocks can be interconnected at the application layer. Here the graph describes the connectivity between nodes at the network layer.
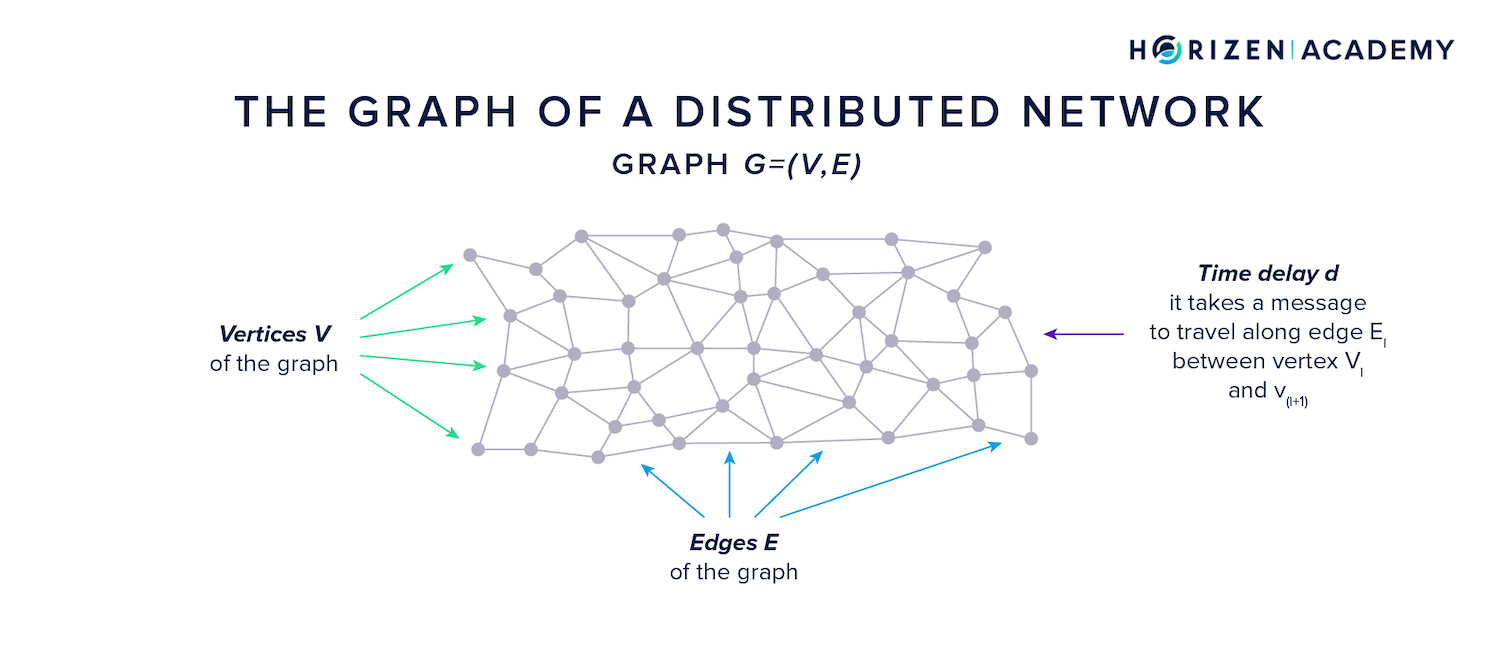
A graph (G = (V, E)) is defined as a set of vertices and edges . Each edge connects two vertices and has a time delay for a message to travel along its path. The graph of a distributed network changes constantly.
This happens when nodes go offline and their peers reconnect to different nodes, or when new nodes join the P2P network. The rate of change can vary, and this has implications on privacy.
There are two extremes when it comes to the dynamicity of the network graph. A fully static graph never changes, which means an adversary can learn the entire graph over time. This means he is in a good position to link IP addresses to public keys.
A fully dynamic graph changes at a rate that prevents an adversary from learning the graph structure and prevents linking IP addresses to public keys. He will only ever know his local graph environment.
Node and Network Failures
When we talked about distributed consensus we introduced two types of malfunctions at the network layer: node failures and network failures.

Nodes can crash or go offline, they can have trouble receiving or processing messages, or they can display Byzantine behavior. When nodes act Byzantine, this means they act randomly and deviate from the protocol. Usually the term is used to refer to malicious behavior.

Network failures are classified using their effect on message propagation, not by the reason that led to the failure.
Usually one of the following models is assumed, and other design decisions regarding the network architecture are based on this assumption:
- In the Synchronous Model, all messages arrive with a known and bounded delay.
- In the Partially Synchronous Model, messages arrive with a bounded delay, but the bound is not known.
- In the Asynchronous Model, the message delay is unknown and unbound. This makes the asynchronous model the “hardest assumption” on which to build a reliable system.
Not only does the consensus mechanism have to account for node failures and network failures, but so does the P2P network itself.
What does a node do in case its peer goes offline? And how does it find a set of nodes to connect to in the first place?
Peer Discovery on P2P Networks
As we said before, peer discovery is more important than content discovery in a blockchain protocol.
Let’s assume you set up a node for the very first time. As soon as you are done, your node needs to connect to other nodes in order to start downloading the blockchain and become functional.
When your node goes live for the first time, the client determines its own IP address. Next it needs the IP addresses of some peers on the network to get started. There are two ways for a node to get an initial set of addresses:
The client contains a list of hostnames for DNS addresses that contain a list of IP addresses for some seed nodes. The client issues a DNS request and receives a list of peer nodes in return.
If this should fail for any reason, the client usually contains a list of hard coded IP addresses of some well-known nodes. All IP addresses a node receives are timestamped.
Once the client has connected to an initial set of nodes, either via a DNS request or the hard-coded seed addresses, it can request more addresses by sending out a getaddr request. When a node receives a getaddr request, it determines how many addresses it currently maintains with a recent timestamp.
The client selects those addresses, up to a maximum of 2500, and returns them in an addr message. An addr message may also arrive unsolicited, for instance when a node advertises its own address to its peers about every 24 hours.
When your node has been offline for a while it tries to connect to the peers it still has in its “address book”. Even if only a few nodes remain active, the client can request new peer addresses by using the getaddr message.
A single synced node stores multiple IP addresses of other nodes. This means a single peer going offline does not pose a problem and can be replaced.
If you want your node to connect to a specific peer, e.g. because you run several nodes and you want them to talk directly to each other, you can manually specify those connections via the addnode command line argument.
Communication Standards on P2P Networks
After taking a look at the topology of a network and how connections between different peers are established, let’s talk about how data is transmitted.
Communication generally happens via messages. Most messages on a blockchain’s P2P network are transactions. The proper appearance of a message or transaction at the application layer has been covered, now we will explain how peers exchange those standardized messages.
Just like a block - each message is essentially a container that holds some data.
The first part of each message is a header that contains some metadata about the message. It begins with a start string to indicate if the message originates from the mainnet or a testnet.
After that the command name specifies what type of message this is. The next field - payload size - indicates how much data the message carries. In the last step, a checksum is added.
There are some messages that don’t have any payload. The getaddr message used to request IP addresses from another peer's inventory does not have any payload.
Synchronizing a Node
Imagine you just set up a node. After the peer discovery stage you have a bunch of IP addresses but still need to sync with all other nodes. This means you have to download all of the blockchain’s blocks. In order to do so, the client will send a getheaders message to your peers.
This triggers the receiving node to reply with a list of block header hashes - up to 2,000 in one message. A block header hash is much smaller in size than a full header, let alone a full block.
In order to reduce communication overhead, peers always exchange the identifiers (hashes) of data objects first, before sending the actual data.
Next, your node will compare the list of headers with its existing inventory. Since your node just got started, there is no inventory so the client proceeds with requesting the actual blocks.
To do so, it sends getblocks messages. The receiving node will reply with its inventory of block header hashes. After comparing the list with its empty inventory, your node will request all blocks to get up to speed.
This is done by sending a getdata message that requests one or more specific data objects from another node - in this case the actual block data.
The getdata message can be used to request blocks, transactions, and other objects. All of them have a unique hash identifier which can be used to request more information.
P2P Network Broadcasting Mechanisms
After a node is in sync with the network, the main influx of information happens via unsolicited messages. Freshly created transactions need to be broadcast to all nodes in as little time as possible, just like new blocks.
The basic function of the broadcasting mechanism is to define a set of rules for how messages are distributed among the nodes of the network.
As we said earlier, the main purpose of the P2P network is to facilitate the communication between peers. In a network that is organically grown and not centrally planned, a somewhat flexible broadcasting mechanism is needed.
This mechanism needs to ensure that all messages reach all nodes within some time period. The broadcasting mechanism affects the order in which peers receive messages and the time it takes nodes to receive messages.
It is desirable for the broadcasting mechanism to display the following properties:
- Low Latency - The maximum time for a message to reach all nodes should be bounded and small. This affects the network’s overall security since data consistency within nodes is crucial. The lower the latency of the broadcasting mechanism the lower the risk of reaching an inconsistent state. A low latency spreading mechanism also means a lower stale rate and less wasted PoW.
- Fairness - All nodes should experience roughly the same latency, assuming they have the same bandwidth.
- Anonymity - A potential adversary should be unable to link transaction messages and therefore the associated public keys to the IP address the message originated from.
There are three broadcasting mechanisms we want to look at further in this article:
Flooding, diffusion, and the Dandelion protocol.
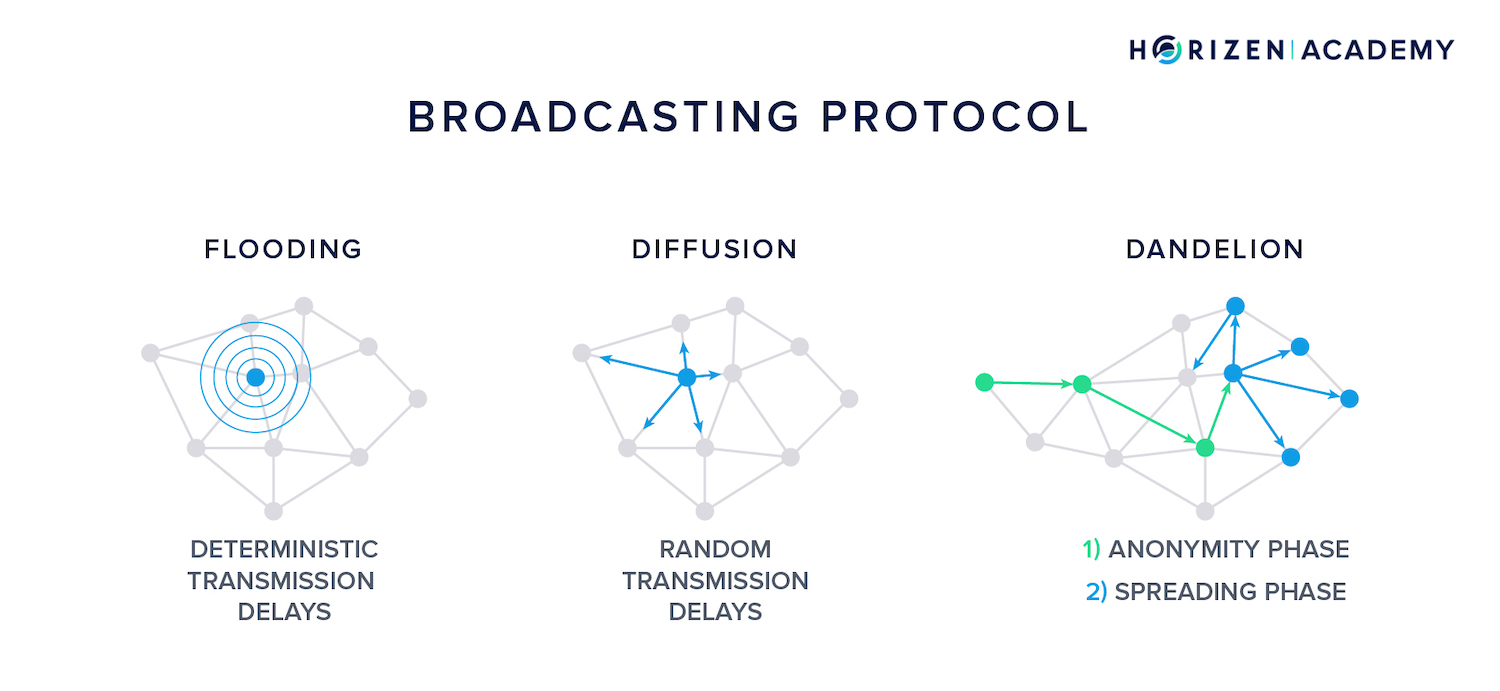
Flooding
Let’s consider a node creating a new transaction:
It wants to broadcast it to the network so it is included in the next block. As a first step, it sends the transaction to all of its peers. In the flooding model, each of those receiving nodes forwards this transaction with a constant time delay.
Once forwarded, a message travels along an edge with a deterministic delay. This means the longer the edge, the greater the time delay.
A message sent from New Zealand to Austria takes longer than a message sent from San Francisco to San Diego.
Although information travels with the speed of light, over long distances these differences become noticeable.
This implies that flooding produces the most predictable spreading pattern. An adversarial node will receive all messages from a given node in a deterministic timing pattern.
Knowledge of these timing patterns together with knowledge of the graph structure allows a Byzantine actor to link IP addresses to public keys - a potential attack vector.
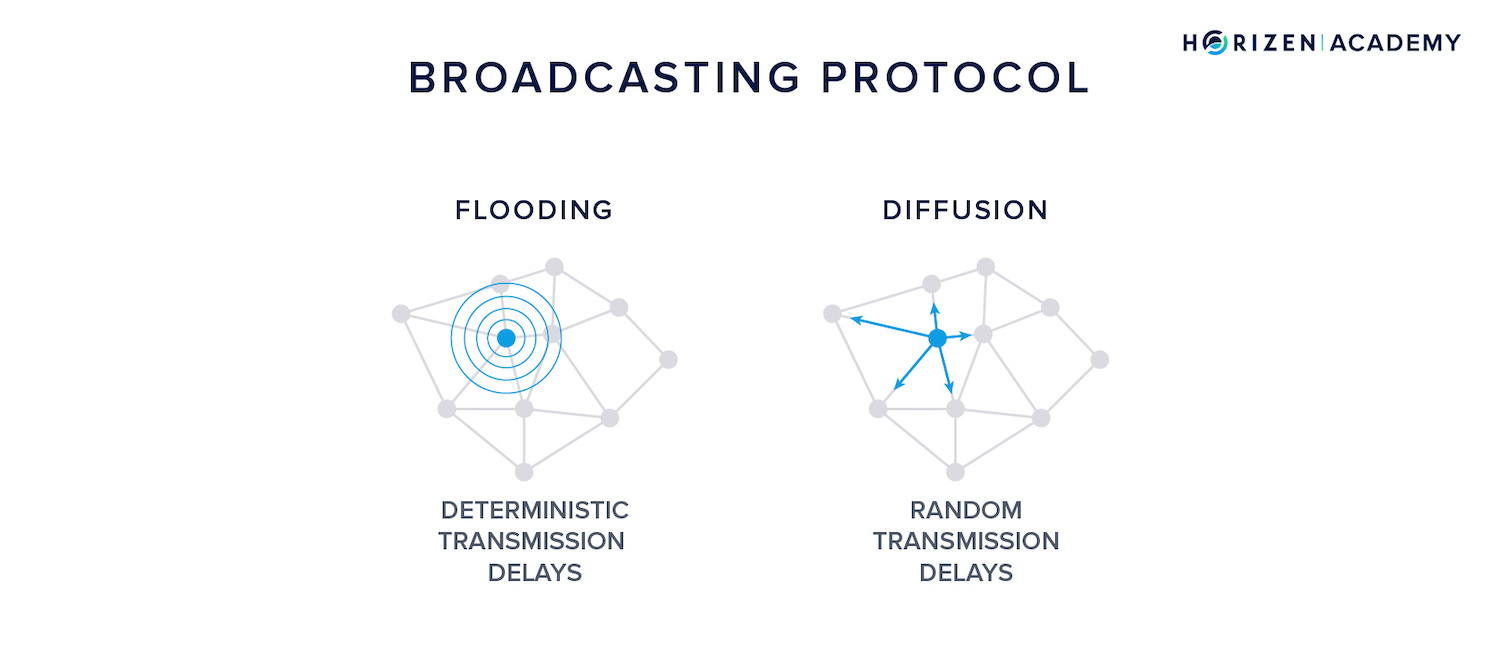
Diffusion
As stated before, diffusion is a refined version of flooding.
The time it takes a message to travel along an edge is still deterministic - physics work either way - but the transmission delay is random. This means a node that receives a message doesn’t forward it to all its peers simultaneously at a constant speed.
Rather, it adds random delays to it.
Currently, diffusion is the preferred method for most public blockchains. In 2015, Bitcoin changed the propagation mechanism from a propagation with a fixed 200 ms delay to diffusion with random delays.
Diffusion makes it harder to derive information from the timing pattern of messages but still follows a simple intuition:
If you imagine a very large graph with thousands of nodes and the source of a message at the center, the message still spreads point-symmetric around its origin.
Diffusion still isn’t perfect. Using sophisticated chain analysis tools, an adversary can derive at least some information from timing and spreading patterns of messages. This holds especially true for nodes that create a large number of transactions and therefore a lot of data to analyze.
One option a node might take to protect its identity is to broadcast messages using a proxy - diffusion by proxy.
But there is another iteration of broadcasting mechanisms: welcome Dandelion.
Dandelion
Instead of using a single node as a proxy to forward messages, Dandelion diffusion happens in two phases: the anonymity phase and the spreading phase.
During the anonymity phase, a message is forwarded via a randomly-selected line on the network graph. Each relayer passes the message to exactly one of its randomly selected peers. The amount of hops in the anonymity phase is also random.
When the anonymity phase is over and the spreading phase begins, the message is broadcast to the entire network using diffusion.
“The core idea behind our proposed networking stack is moving-target defense: we harness randomness in both the graph structure and the spreading protocol, thus making it difficult for adversaries to infer the source of a transaction. The key is to do so without harming latency and fairness guarantees.” - Viswanath, Redesigning P2P Networking Stack of Cryptocurrencies for Anonymity.
Dandelion is implemented in Beam and Grin, two different implementations of the MimbleWimble protocol.
Privacy and Security on Peer-to-Peer Networks
Most privacy preserving techniques are not effective if messages can be linked to IP addresses. Even with simple techniques and minimal knowledge of P2P graph structure up to 30% accuracy in linking messages to IP addresses.
In order to quantify the level of anonymity a spreading mechanism provides, two metrics can be applied:
“Precision and recall are natural performance metrics. Recall is simply the probability of detection, a common anonymity metric that captures completeness of the estimator, whereas precision captures the exactness.” - Bojja, Fanti, Viswanath - Dandelion: Redesigning the Bitcoin Network for Anonymity
To assess the security and privacy properties of the broadcasting mechanism, one assumes there are two types of nodes:
Honest nodes and adversarial nodes colluding to deanonymize users.
An attacker can apply two different techniques to deanonymize users, eavesdropping or the spy-based approach:
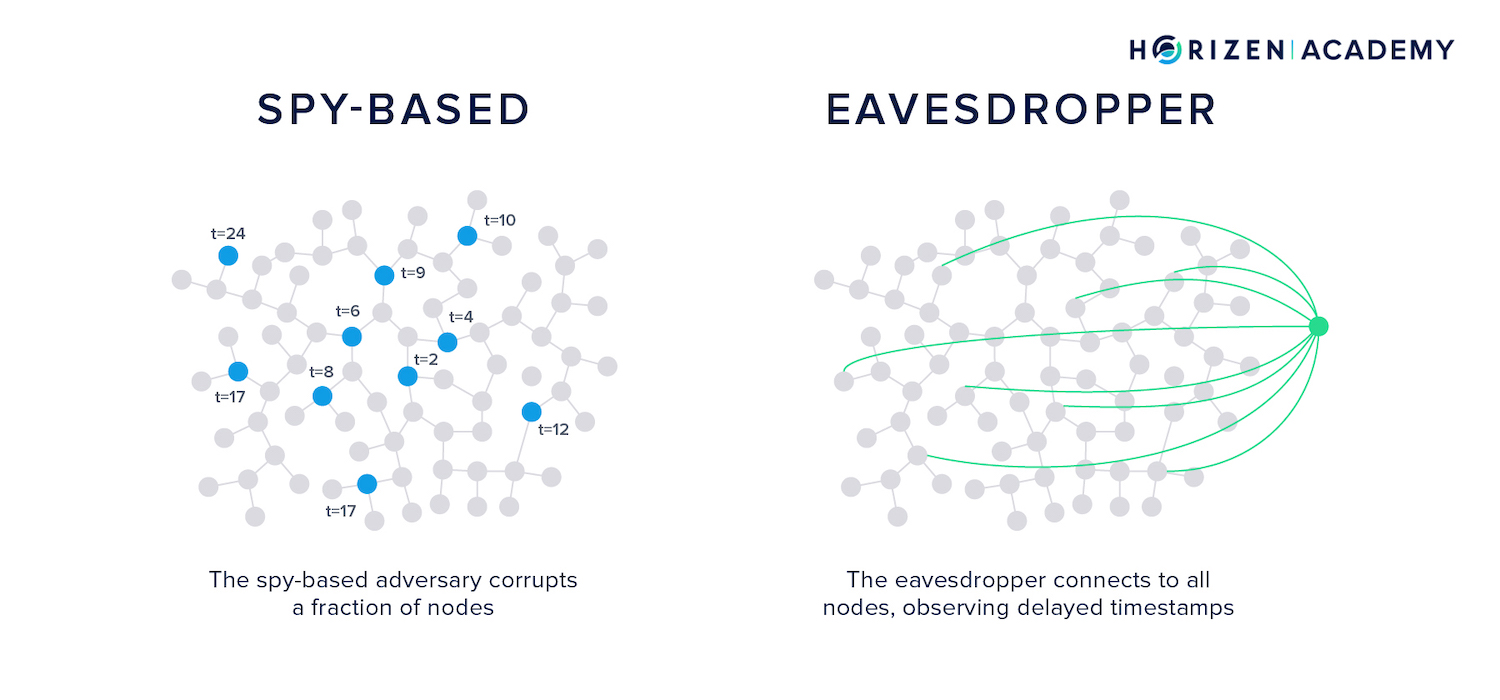
The eavesdropper connects to as many nodes as possible using a highly performant node. This node can establish several connections to a single honest server, with each connection coming from a different IP address.
The honest node doesn’t realize that more than one of its connections originates from the same node.
The eavesdropper node listens to all relayed messages on the network without relaying any content itself. The attacker running the eavesdropper node thus gets information about the network topology and learns its graph over time.
The spy-based adversary corrupts a fraction of nodes and observes the timestamps of broadcast messages.
“This is different from the eavesdropper adversary because the eavesdropper only observes delayed timestamps, and it does so for all nodes, including the source [of the message]. Precise analysis of the spy-based adversary has not appeared in the literature.” - Giulia Fanti, Pramod Viswanath, Anonymity Properties of the Bitcoin P2P Network
Incentivizing Infrastructure
Most blockchains provide little to no incentive for running nodes on the network. In the early days of Bitcoin, most nodes also mined BTC and therefore collected the block reward.
Another good reason to run a node is to safely accept payments. Most wallets are actually light nodes. They connect to a full node in order to “speak” with the blockchain.
This means they have to trust the full node operator to feed them truthful information. By running a full node yourself, you don’t have to trust anybody - you can verify for yourself.
Still, few people transact regularly enough to run a time intensive full node.
Secure Nodes and Super Nodes
Horizen also incentivizes node operators financially because running a node comes at a cost. It takes time to set up, you need to set up or rent a server, and the node operator has to update the software occasionally.
On the Horizen network, miners receive 60% of the total block reward, 12.5 ZEN. The other 40% is used to fund the infrastructure (Secure Nodes 10% and Super Nodes 10%) and the non-profit Zen Blockchain Foundation 20% for the development of the protocol.
Because Horizen wants not just many, but also capable and robust nodes, a node has to fulfill a set of minimum requirements. Each node needs a valid TLS certificate, needs to be up and running for at least 92% of time, and meet certain memory and computational power requirements.
You can find out more about the requirements for Secure Nodes and Super Nodes here.
On a permissioned blockchain that a consortium of companies is running, e.g. to track a supply chain, the incentive to maintain the ledger is to have access to valuable business data without having to trust a third party.
We believe that Web 3.0 will benefit largely from the emergence of distributed networks and that we will see a transition from centralized services to decentralized ones.
Those computational requirements are verified using an interactive challenge-response protocol - a type of Proof of Work if you will. Nodes receive computational challenges on a regular basis and by monitoring the time it takes them to respond to these challenges, one can derive an estimate on their capabilities.
Nodes need to meet a certain target with their response time, otherwise they are not considered eligible for node reward payments.
Secure and Super Nodes are not just a means to create some sort of masternodes, they will be crucial for our Sidechain model. Node operators will be able to choose whether they want to support sidechains, and if so, which ones.
We expect to see some interesting economic models with dApps built on our sidechains. dApps should incentivize node operators to support their sidechain, just like they would usually pay for the infrastructure their service is built on.
Horizen EON is our first public proof-of-stake sidechain and a fully EVM-compatible smart contracting platform that allows developers to efficiently build and deploy dapps on Horizen, while fully benefiting from the Ethereum ecosystem.
Summary - P2P Networks
Peer-to-Peer networks offer great robustness or fault tolerance at the expense of efficiency. Every node is performing the same task on the network and acts as a client and a server at the same time. If one of your peers goes offline you just connect to another one.
If you run a node and happen to go offline for a while, you need to reconnect at some point to get updated by your peers on the blocks that you missed to become fully functional again.
Two compelling reasons for running a blockchain on a public P2P network are the low cost of starting the system and the high level of resilience this infrastructure offers.
The P2P network can be represented with a graph, where nodes comprise the vertices of the graph and the connections between peers are the edges connecting the nodes. The main purpose of the network is to facilitate the communication between the different network participants.
While other distributed infrastructures are often optimized for content discovery, as in the case of BitTorrent, blockchain P2P networks are optimized for peer-discovery because all nodes store the same content.
The broadcasting mechanism used to distribute messages across the network affects the level of privacy a node experiences. When attackers are able to link public keys to their originating IP addresses, this opens the door to various attack vectors.
We talked about flooding, a mechanism where messages are forwarded with a constant time delay, diffusion, where the time delay is random, and Dandelion, where broadcasting happens in two stages: the anonymity phase and the spreading phase.
Lastly, we explained why we incentivize node operators on the Horizen network and what conditions these incentives are tied to.