Blockchain - A Data Structure
If you have read up on Bitcoin, blockchain, and cryptocurrencies before, you may know there is a distinction between:
- Blockchain technology in general
- A protocol, or the rules of a specific blockchain
- The currency that is running on top of this blockchain - if there is one
You can look at blockchain in many different ways, on the one hand, it is a way to store data and, on the other hand, a language or protocol to transfer value.
Looking at blockchain through the lens of cryptocurrencies has been the dominant narrative until recently. Bitcoin is the first thing most people will associate with blockchain technology, but storing cryptocurrency transactions is only one use case out of many.
Let’s take a closer look at the first use case for blockchain technology - digital money. To have a monetary system without central control, you must have a special and sophisticated way to handle all the data produced with each transfer.
Imagine if every person could access and modify the databases kept by banks. It would be a disaster.
In order to make decentralized money a reality, a method of accounting had to be developed - the UTXO model, also referred to as triple-entry accounting. You can compute every account balance at any time by storing all transactions in a digital ledger.
A digital ledger used for digital money requires a set of properties that were not achievable before blockchain came along.
The Blockchain is a Type of Data Structure
A blockchain is a data structure in the eyes of a computer scientist.
This structure stores information reliably, regardless of being in a trustless environment. A data structure may sound technical at first, but its function is exactly that, it structures your data.
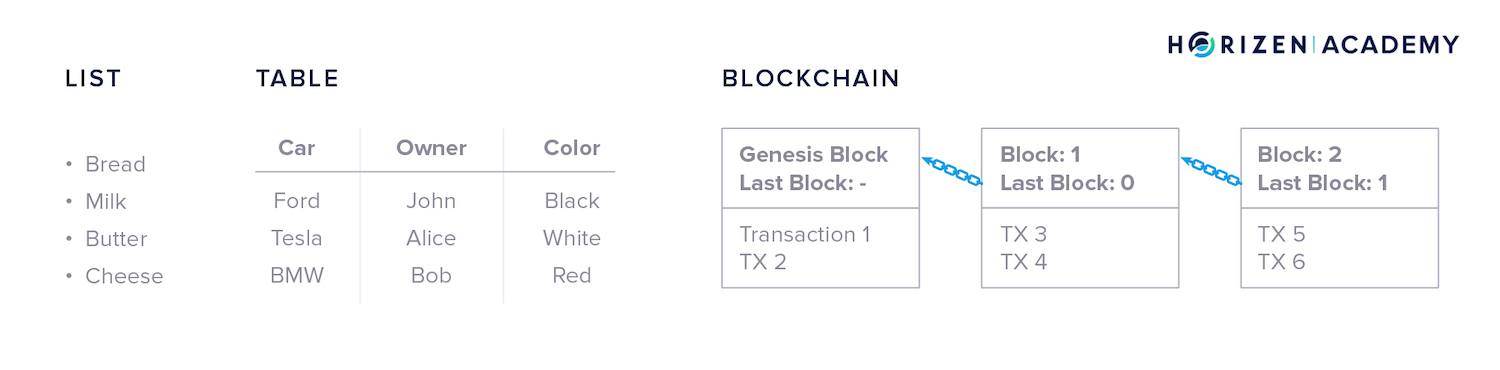
Lists or tables are familiar types of data structures.
You likely use one of these two methods each time you write down information on paper. There are many types of data structures in the digital world, including blockchain.
The term blockchain comes from the structure that stores your data. All data becomes separated into blocks. Every block states which block came before it creating a “chain” of blocks. Stating which block came previously is commonly referred to as referencing.
A Database: Efficient but Centralized
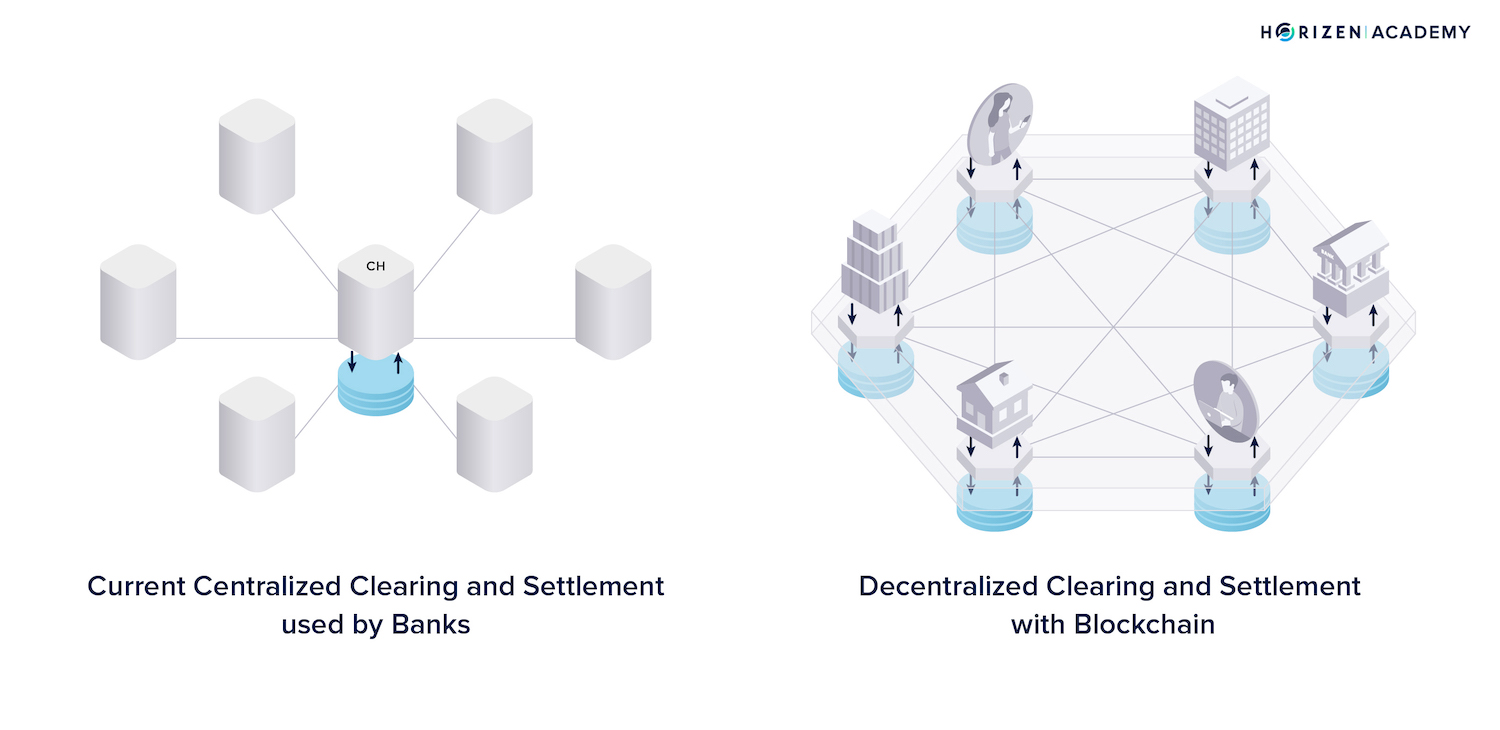
A database is a highly efficient data structure. Databases are an excellent way to store large amounts of data, but are usually operated by a central entity.
Your bank, your favorite social network, or online merchants, all use databases to store your data.
These entities decide who can add data to the database and who can access it, but they also have the power to change or delete data. You can edit your social media profile freely. Your friends can see that information, but if you violate the site’s Terms of Agreement, these social media platforms can delete your post.
The central entity has the last say in what stays on the platform. Centralization can be both good and bad when it comes to a social network, but this would not be a good feature when looking at data structures that store your money.
Centralized databases are a lot more efficient, not only because of the way they store data, but mostly because the database is maintained by a single entity.
A Blockchain: Less Efficient, but Decentralized
Many different entities, or peers, operate a blockchain. These peers don’t know or trust each other, and are therefore trustless. The good thing is that they don’t need to trust each other.
Many peers keep a copy of the data, and no single peer has the power to change or censor the data. Participants, or nodes in technical terms, consistently communicate to keep each other updated on new events. Most of these events on the blockchain are commonly transactions.
There is no centralized entity, like a bank or clearinghouse, responsible for accepting and processing new transactions.
Cryptocurrencies are permissionless because every individual abiding by the rules of the protocol can create a wallet and send a transaction without needing to sign up to use the service.
Cobalt is a secure and easy-to-use web extension wallet for the Horizen cross-chain ecosystem. Trustworthy, reliable and built to easily manage your assets.
The transaction is then broadcast to the network, and every participant (or node or peer) keeps a copy of it. A node can be operated by a person, a store accepting crypto, or a bank; it makes no difference who you are.
The amount of copies makes a blockchain slower than a database but makes it more secure.
Where Does the Term Blockchain Come From?
The blockchain does not keep data in a single huge continuous ledger, but separates the data into blocks. These blocks are then connected like individual pages in a book.
That is how the term blockchain came to be.
Imagine a bookie recording entries using single pages of a book instead of one large scroll. Every few minutes, he starts using a new page and adds a reference to the last page - “this page follows page x”.
The reference he includes “chains” the pages together. He can easily arrange the pages if he ever drops them because each page references its predecessor.
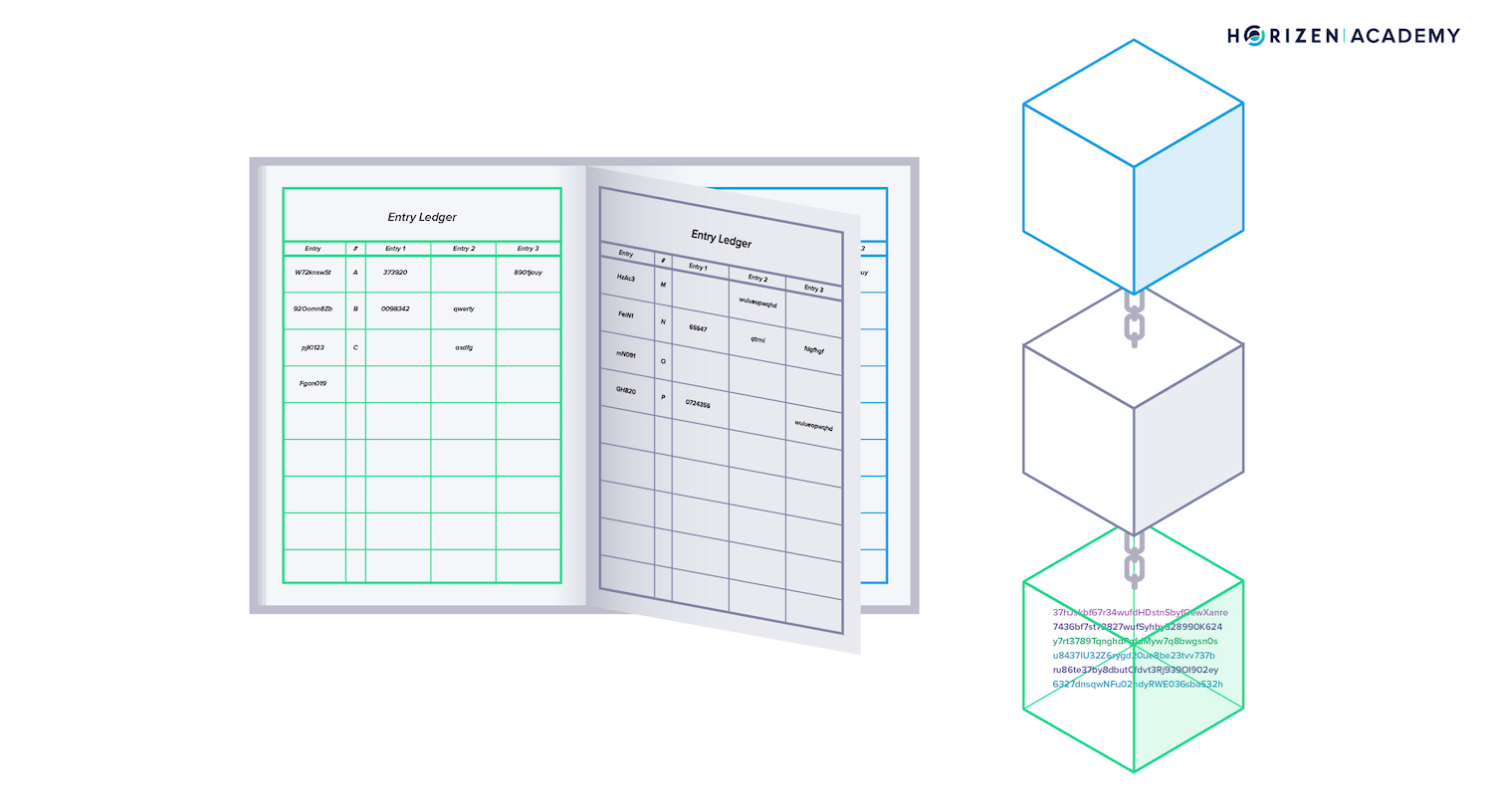
One of these single pages represents a block in this comparison, and the pile of the pages he already used represent the blockchain. Instead of one bookkeeper, there are many of them working simultaneously on a blockchain.
Miners are the bookkeepers of a blockchain, they are the ones creating new blocks.
The Blockchain is a Data Structure
A data structure is a way to store, organize, and manage data.
A data structure enables you to access, add, modify and search the data contained within it. Some of the most common and basic data structures include arrays, linked lists, and hash tables.
Let’s develop an understanding of data structures before we look at blockchain itself.
Common Data Structures
Arrays
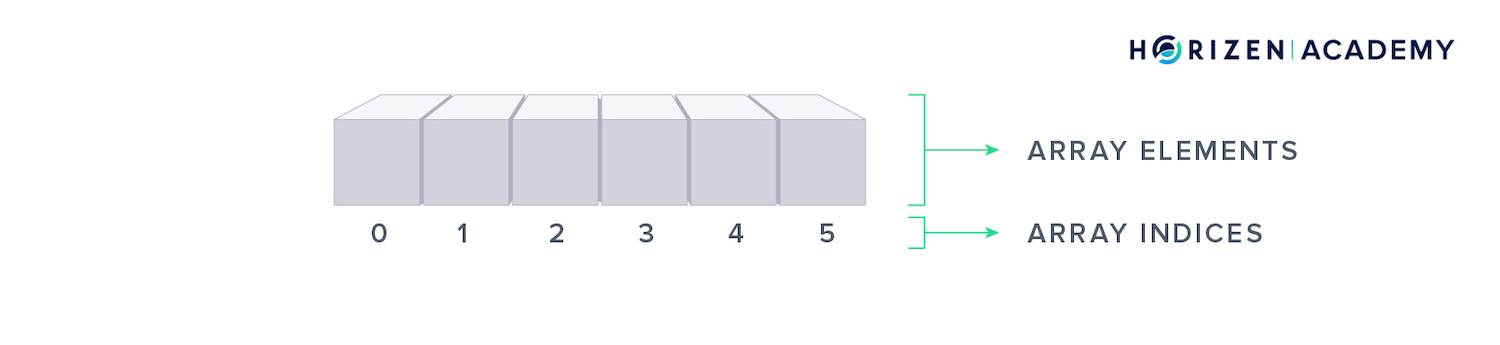
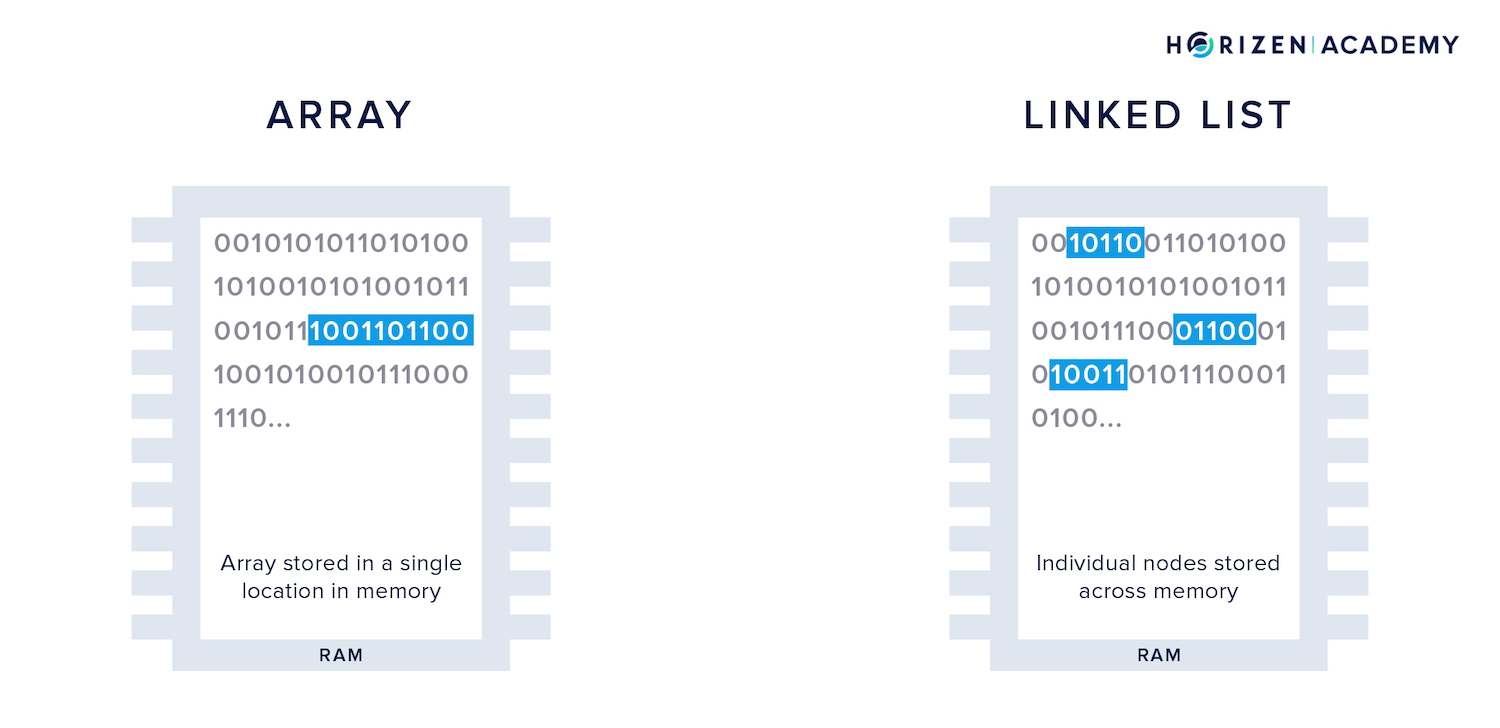
An array is a number of enumerated elements. These elements can be numbers, letters, words or even entire files. The indices allow you to access any element individually, so if you want to modify an entry in an array and you know its location, you have instant access.
Arrays are one of the purest forms to store data. Arrays are useful when you know how many data elements you need to store and how large each data element will be. Your computer will calculate the required storage from those inputs and set it aside, preventing other programs from accessing this partition of your memory.
The drawback to partitioning memory is that reserved memory may be too small for future expansion. In this case, the entire array must be moved to a different location.
Each element of an array has an index that starts at 0. You can instantly access and modify an element if you know where you stored it. If you don’t know an element’s location, you must do a sequential lookup.
This means you check the elements one by one - starting at index 0 - until you find it.
Arrays are useful for their simplicity and instant access property.
Linked Lists
Nodes are the data elements in a linked list.
A node comprises at least one data object and a pointer to the next element. This pointer’s function is to tell your computer where to find the next element of the list.
If you look at the first piece of data on the list and wish to access the second one, you will look at the pointer that directs you to the next node. It is easier to add data to a linked list through expanding it by an extra node than it is to add data to an array by increasing the number of elements.
What you don’t have with a linked list is instant access.
If you are searching for a specific piece of data in your linked list you will look at the first node, the head of the linked list. If it is not the element you were looking for, you follow the pointer, that will lead you to the next node.
If this node does not contain the data you were looking for either, you continue by following the links throughout all nodes until you find the desired data.
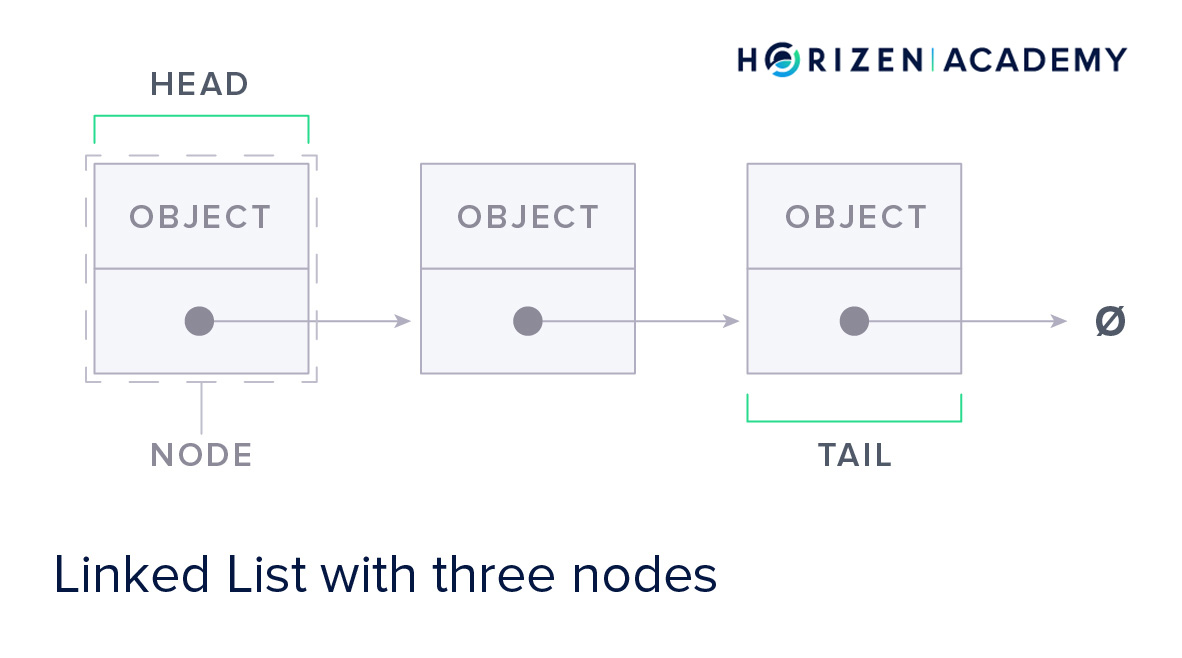
Programs that use a linked list to store data don’t have to know how many data elements you want to store beforehand, but the linked list does need to know what each element consists of. As previously stated, data elements of a linked list are called nodes. Each node can contain several objects of different types.
For example. If you were to store information about cars in a linked list, you could define a node as the set of information about the brand, model, year produced, and license plate.
The first element of a linked list is called the head, and the last one is called the tail.
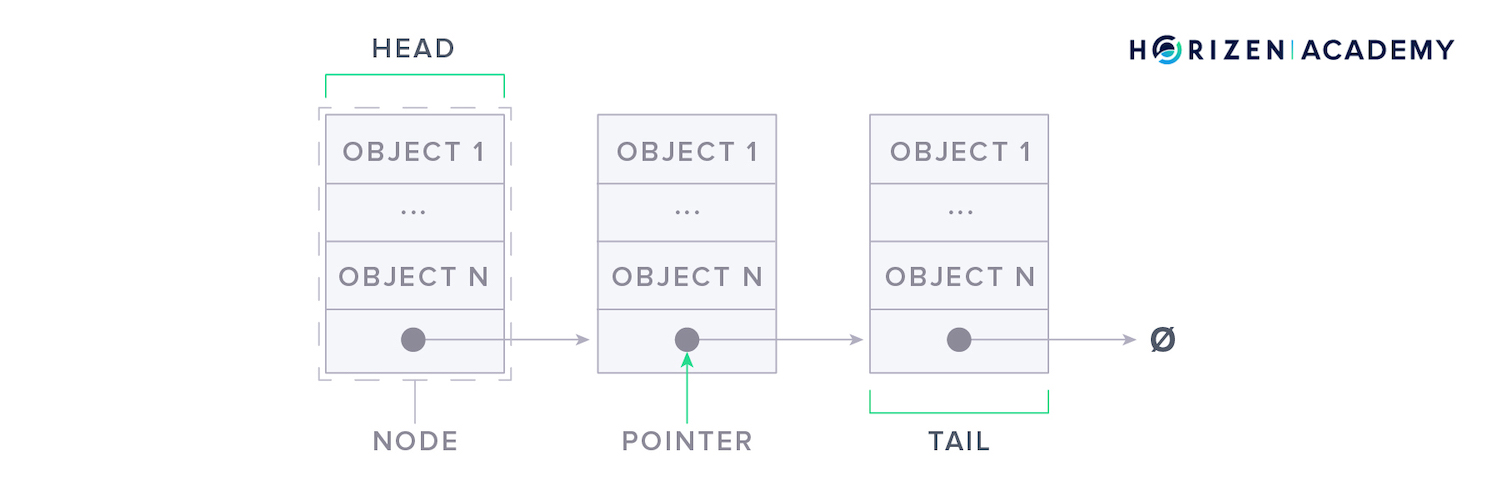
Each node also contains a pointer to the next node.
The pointer tells your computer where the following node is located in memory. This allows you to expand a linked list easily because the data doesn’t have to be in a single, continuous location in memory.
When searching for a piece of data, your computer will check the head of the linked list first. If it’s not there, it will look at the pointer, go to the location in memory where the following node is stored, and continue following pointers until it finds the desired data.
This method of finding data is called sequential lookup.
Using a linked list gives you more flexibility in terms of expanding the list later on by adding new nodes, but unlike arrays, it doesn’t give you instant access.
Hash Table
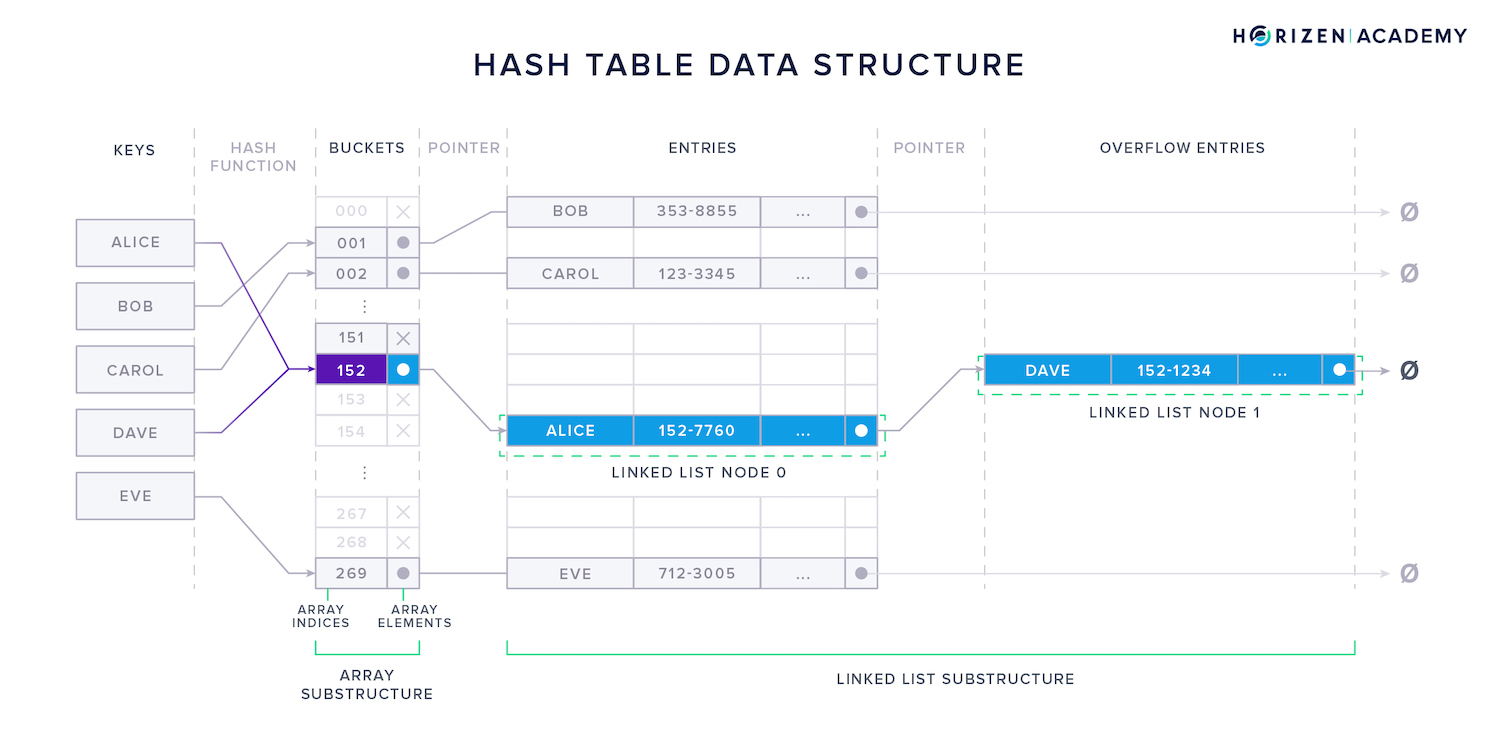
The last data structure we want to look at before moving on to the blockchain is the hash table. The data elements you are storing in a hash table are called keys. To store a key, it is first hashed using a hash function.
All you need to know at this point is that a hash function uses an argument of variable length as input and produces an output of fixed length. In the example below, the output is a three-digit number.
The keys are mapped to buckets by their hash value, for example, if "Alice" hashes to 152, it is stored in this bucket. The buckets can be stored in an array because the output space of the hash function is known. Each bucket can instantly be accessed through its index.
A hash table is useful when you need to store many related data elements, like in a customer database. Initially, you could create a customer ID by hashing the customer’s name. Now there is a dedicated location to store purchases, refunds, or contact information.
Whenever you need to access the customer data, your computer would hash the name you are looking for to find the bucket efficiently and add, change, or delete data.
The hash functions used for hash tables are usually not collision-resistant. This means two keys might produce the same hash and would consequently be mapped to the same bucket.
A linked list within the hash table is used to store several keys within a single bucket. In the example below, bucket 152 stores a pointer to Alice’s data in the first node, which points to the second node containing Dave’s data.
If the hash table is well-dimensioned, the cost, or the number of instructions/computations, for each lookup is independent of the total number of elements stored in the table. Hash tables give you instant access without even knowing the location of every element in memory.
The location is defined by the data itself, making it convenient for systems that have to store large amounts of data and repeatedly access them.
There are many different data structures; each of them comes with some trade-offs, and depending on the use case, one might choose one over the other. Sophisticated data structures often leverage several more simple concepts in combination to achieve the set of desired properties. We chose the three examples above to show how an array and a linked list can be used to build a hash table.
The blockchain is a rather sophisticated data structure, made up of many sub-structures. It gives us a set of properties that are paramount to building a decentralized ledger for digital money.
The Blockchain
The blockchain is like a linked list in the context of data structures.
The blockchain organizes data by splitting it into subsets or containers, referred to as blocks. The blocks are quite analogous to nodes in a linked list. Each block contains a reference, which is the hash of the preceding block.
This serves as a link to the preceding block and establishes the order throughout the chain of blocks.
Each block contains several elements. The elements of a block are generally separated into the block header and its transactions. While the transactions in a block account for most of the data, the block header contains essential metadata about each block, such as a timestamp and block height.
The key difference between a blockchain and a linked list is that each reference in a blockchain is cryptographically secured, and therefore tamper-evident. In contrast, the pointers in a linked list can be changed at any time without affecting the integrity of the data.
The secured references establish order throughout the blocks and effectively make the blockchain an append-only data structure where new data can only be added with new blocks. This means you can only add data to a blockchain by appending it to the front.
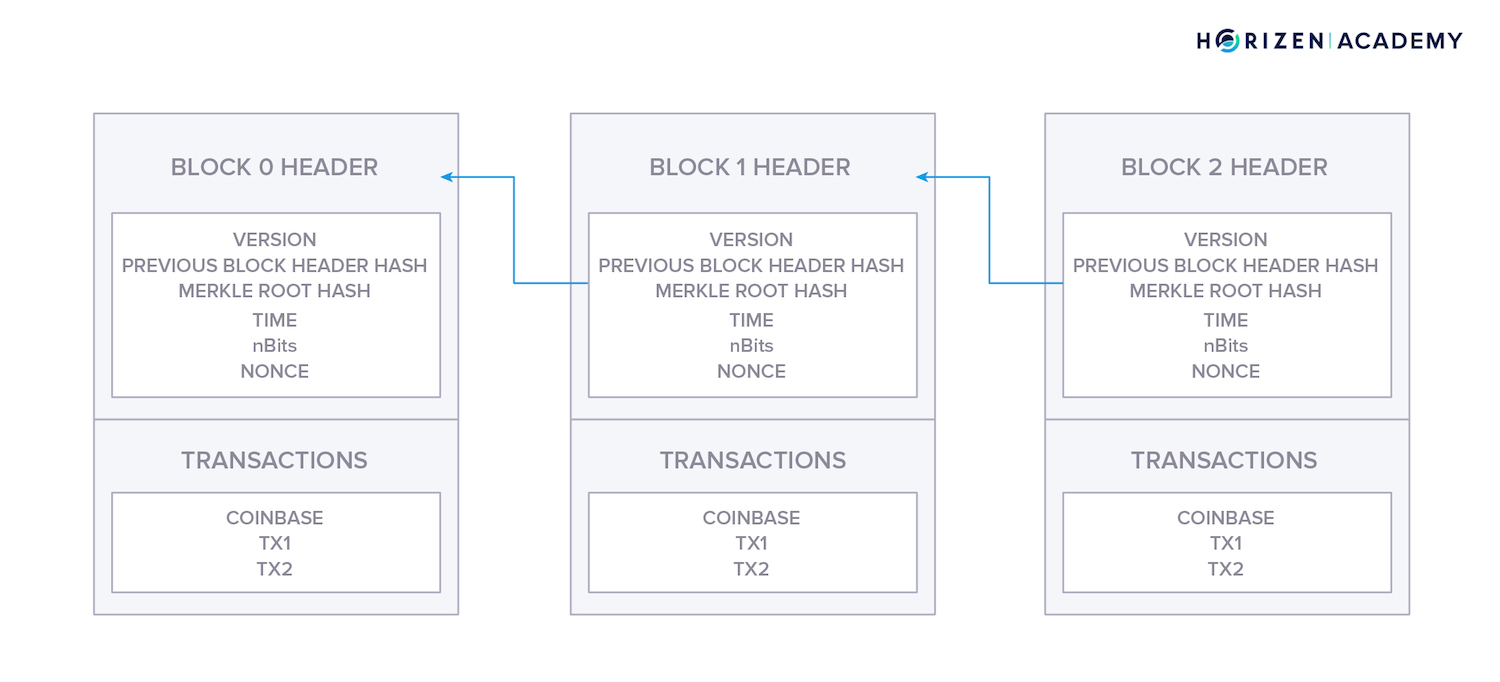
The hash value of the previous block header is included in the following block as a reference because the block hash depends on the data of a block, even changing a single character in one of the transactions would invalidate the reference.
The secured links are constantly checked for validity. If you were to insert a malicious block in the middle of a blockchain or change data in an existing block, for example, between Blocks 1 and 3 in the graphic below, you could include a reference to its predecessor, Block 1.
Still, it would be infeasible to make Block 3 reference your newly inserted block.
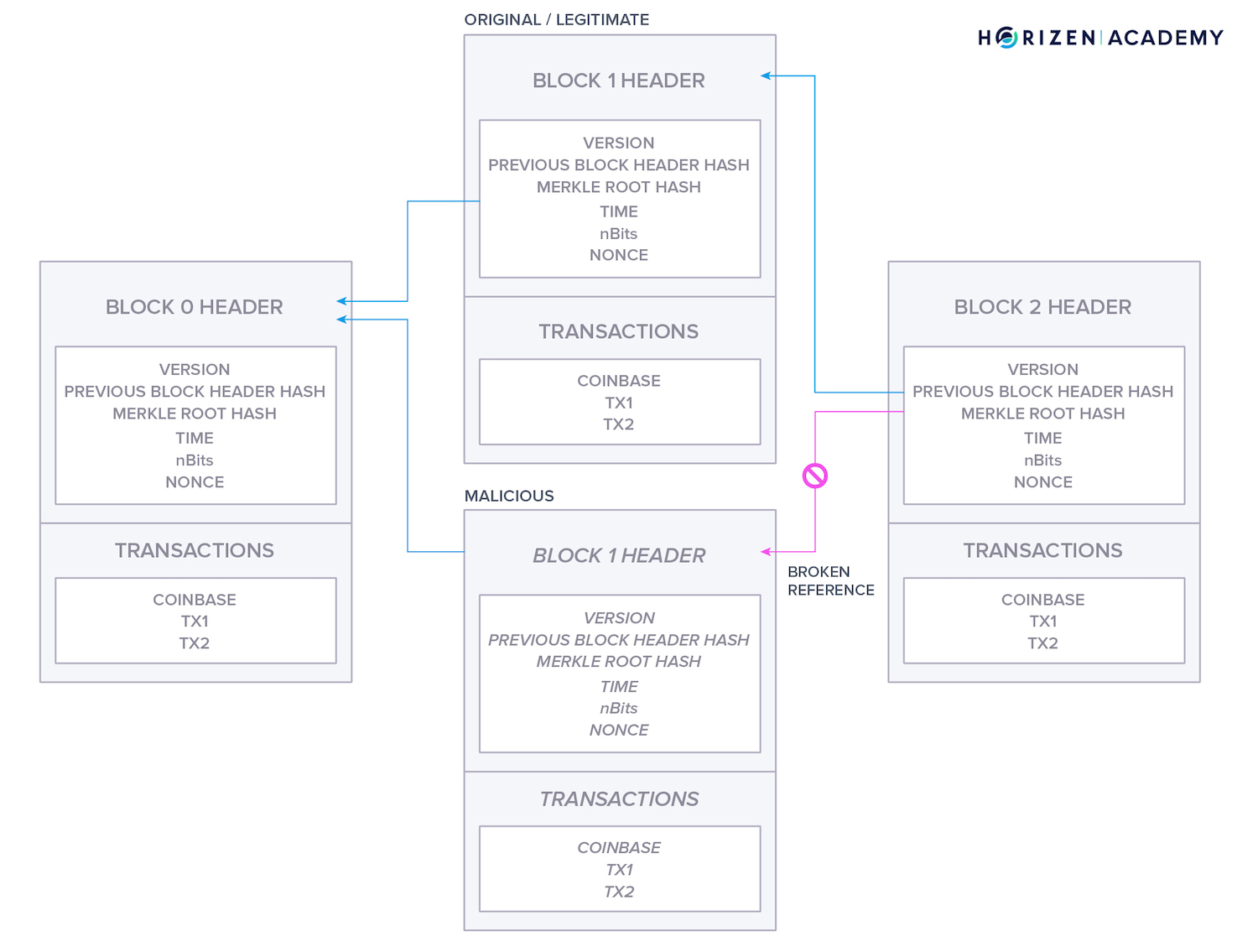
Each new block built on top of an existing block is commonly known as a confirmation. The older a block gets, the more confirmations it will have. Each confirmation makes tampering with the data in a block more difficult because you have to recreate additional valid references.
To tamper with its data, you would have to recreate one valid block including a new valid reference. With each confirmation, you would have to recreate an additional block. This means the older the block, the more certain you can be that no changes to the block will occur.
It is important to note that it is not the data structure that makes data on the blockchain immutable. The information alone is tamper-evident only. Changes are easy to detect. There is no immutability if there are no strong consensus rules in place, and a sufficiently large number of nodes on the network.
The incentives need to be structured so the majority of participants will follow the protocol and reject invalid blocks.
The references between blocks don’t just depend on the order of blocks, but also on the data contained within each block. It is not possible to add or delete data from a block in the blockchain. This property is the foundation of the trust people put in the data stored in a blockchain.
The data structure of a blockchain is naturally tamper-evident. Any change of data breaks the references of all subsequent blocks.
While it is not possible to change or delete data, it is easy to add data in a new block to the chain. For example, you could add a new transaction on a cryptocurrency blockchain.
The transaction is easy to verify because all the preceding transactions recorded on the network are immutable - this makes the verification of transactions simple. When Address Y wants to spend amount X, it must have a balance of at least amount X.
The relationship between the data structure, the protocol and the consensus mechanism, and their inner workings, are what make the blockchain a powerful tool for building trustless digital money.
The Properties of Blockchains
Let’s take a look at the properties that a blockchain offers before taking a closer look at the data within a block. We will assume a decentralized setting without a central authority and a robust consensus mechanism.
Current Shortcomings
It is appropriate to issue certain caveats first. The development of a blockchain is stricter and slower compared to traditional databases. A bug that corrupts the integrity of data makes the entire construction useless. Hence, development must be done very carefully. In a centralized setting, a bug might be easy to fix, but in a distributed environment without a central authority, this becomes very difficult.
Second, incentive design is an integral part of building a blockchain. There is always a cost associated with adding data to a blockchain. This cost must be high enough to prevent large amounts of useless data from being added, but at the same time, it needs to be low enough not to become prohibitive. Once deployed, fixing is not easily done for the same reason as above.
Maintaining a blockchain is also orders of magnitude more expensive than a traditional database. Data is not recorded once but thousands of times. Data is also verified by every full node on the network, thousands of times in parallel. Additionally, the transmission of data is inefficient by design, causing the cost of maintenance to rise. This redundancy in every step of using a blockchain makes it hard to scale.
Benefits of Using Blockchain
All of this overhead can only be justified through utility. Having global money with a predictable inflation schedule, and trustless transactions without central control and single points of failure, are arguably enough utility to use a blockchain for this purpose. For many other use cases, time will tell if blockchain poses a suitable solution.
Just as with the immutability attribute, it’s important to note that the current shortcomings of public blockchains result from being run in a distributed fashion, rather than the data structure. While a high level of redundancy makes the data secure, it is inefficient by definition.
In turn, you can get some unique properties with a blockchain, that if needed for the specific use case, make it invaluable. The main factor distinguishing a blockchain from a normal database is that there are specific rules about how to add data to the database.
This set of rules, or protocol, can achieve the following traits:
- Consistency: Newly added data cannot conflict with data already in the database.
- Tamper Evidence: Append only data structure that makes it immediately apparent if data has been changed. Coupled with a strong consensus mechanism that incentivizes rejection of invalid blocks this results in immutability.
- Ownable: Data can be attributed to a sole owner. The data is publicly verifiable, but only the owner can make changes to it. In the context of cryptocurrencies, this means everybody can see the transactions, but only the owner can spend a UTXO.
- Distributed: The database is consistent without a central party acting as a gatekeeper. This results from the protocol incentivizing correct behavior. Consensus and fault-tolerance are the holy grail of distributed systems that Bitcoin achieved for the first time in history.
You get immutability of data only if there is a strong consensus mechanism in place that makes the network participants decline invalid blocks. Otherwise, a blockchain is only tamper-evident.
After looking at the properties that result from the design, let’s take a look at how it is constructed. First, we look at the blocks themselves. Next, we introduce a concept that allows us to create an efficient summary of all transactions - the Merkle tree. Lastly, we look at the transactions themselves that make up the majority of data in a block.
The Structure of a Block
Blocks consist of a header that contains essential data about the block - a sort of summary. The largest part of a block in terms of storage comprises the transactions.
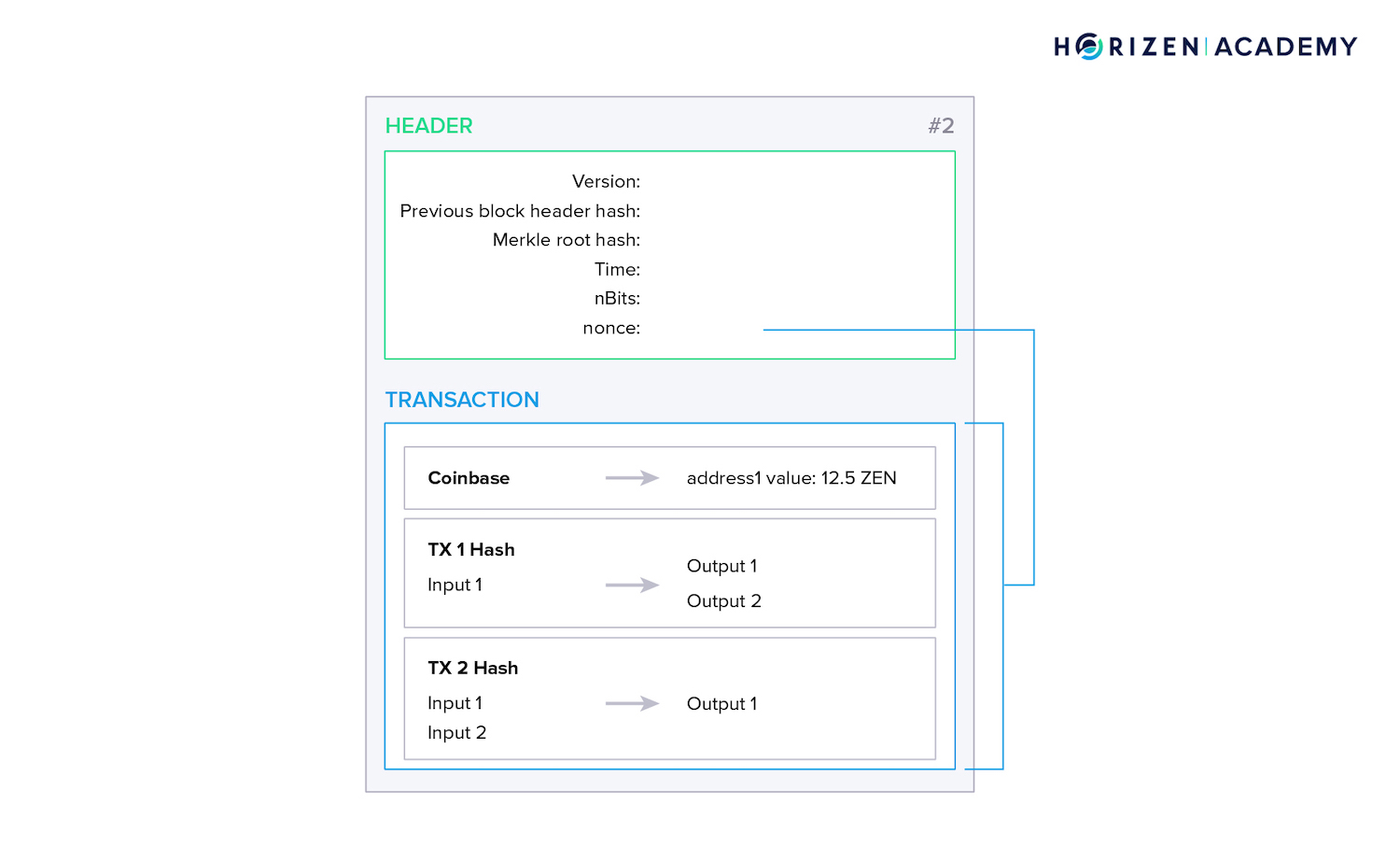
The Block Header
The block header contains the most important information about a block.
- The Version indicates which software version the miner of the block used and which set of block validation rules were followed.
- The previous block headers hash hashPrevBlock serves two purposes. First, it establishes an order throughout the chain of blocks, and second, it ensures no preceding block can be changed without affecting the current and all subsequent blocks.
- The Merkle Root Hash - hashMerkleRoot - represents a summary of all transactions included in the block.
- The Time is the Unix epoch time when the miner started hashing the header for the mining process.
- The Bits or nBits are an encoded version of the current difficulty of finding a new block.
- The Nonce - or number used once - is the variable that miners change to modify the block headers hash for its value to meet the difficulty. This process is covered in detail in our article on mining.
Merkle Trees play an important role in ensuring the integrity of data in the blockchain. They are also used in other systems such as IPFS, the InterPlanetary File System and several implementations of NoSQL databases. Let’s take a look at how they work and what they do before we continue with what a transaction looks like from a data perspective.
Merkle Trees
A Merkle tree is a data structure used within blocks. The transactions in a block make up the "leaves" of the Merkle tree.
The resulting Merkle root serves as a summary of all transactions and is included in the block header.
Constructing a Merkle tree goes like this:
- The coinbase transaction rewarding the miner with new coins is placed first, followed by all other transactions in the block.
- First, each leave (transaction) is hashed.
- Next, the hashes of the two transactions are concatenated and hashed again.
- If the number of transactions is odd, the last transaction’s hash is concatenated with a copy of itself.
- This process continues until only a single hash is left - the Merkle root.
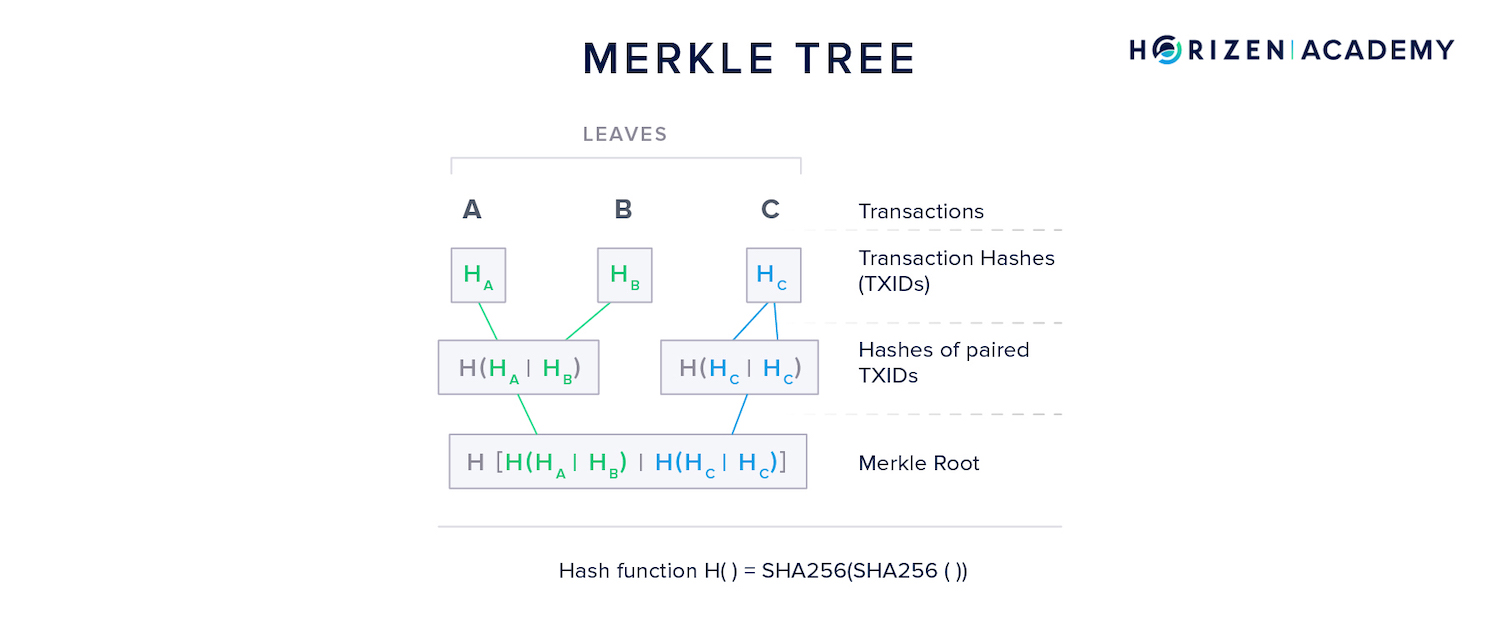
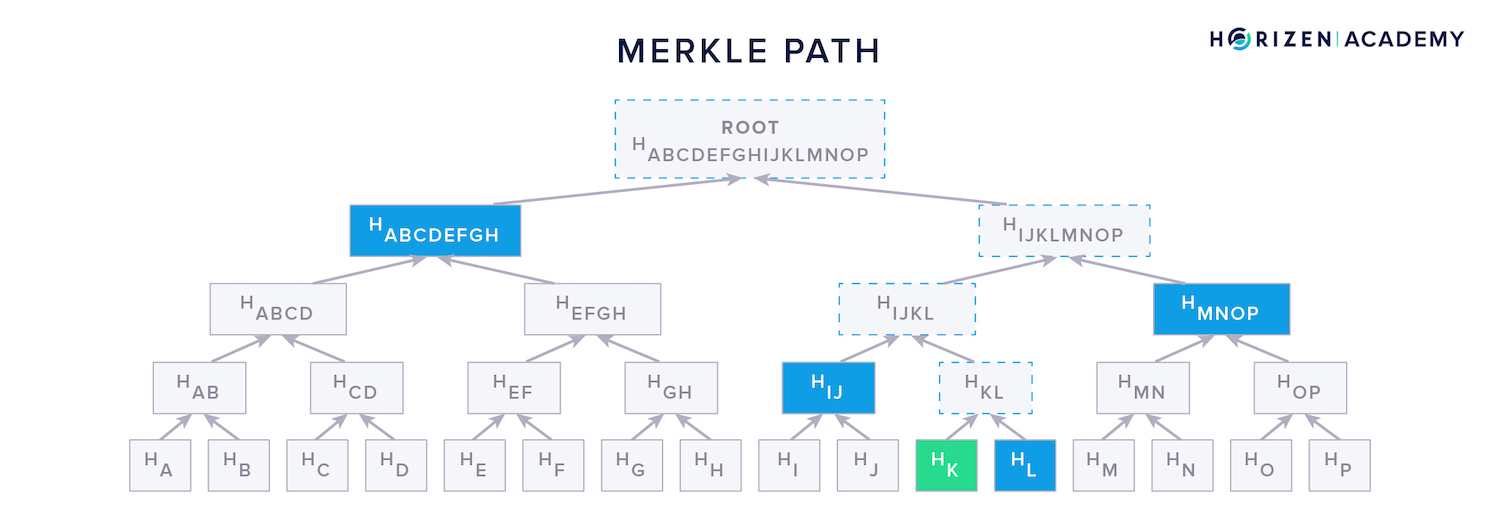
The Merkle path is simply the set of hash values needed to reconstruct the entire tree. The Merkle path for transaction K consists of the hash of transaction L it is first concatenated with and the combined hashes , and lastly, .
Those four hashes, together with the original transaction, allow a verifier to check the tree's integrity.
What does a Transaction look like?
Every transaction, except for the coinbase transaction, has at least one input and one output. When you create a transaction, you are spending UTXOs - unspent transaction outputs - using them as inputs to the newly created transaction. At the same time, you create one or more new UTXOs that are then spendable by the payee - the new owner.
To be precise with our language, we introduce a new concept here: outpoints. An outpoint is a data structure characterizing a particular transaction output. It includes the transaction id the output was created in, as well as the output index identifying a specific output among potentially many outputs created in the transaction. The outpoint is, therefore, just a more distinct way of referring to what is generally known as an output.
A transaction is a message to the network informing it about a transfer of money. This message is standardized and composed of the following information:
- Version: Just as every block indicates the software version it was created with, every transaction includes this information.
- tx_ in count: Is the number of Inputs used - so the number of UTXOs consumed.
- tx_ in: Each input used is characterized by four data points: the outpoint it spends, the size of the signature required to spend that outpoint, the signature itself, and the sequence number. The sequence number can be used to modify the spending conditions of an outpoint, but we are getting ahead of ourselves.
- tx_ out count: Is the number of outputs created in the transaction.
- tx_ out: Transaction outputs. Each output is characterized by three data points: the amount spent, the size of the spending condition, and the spending condition itself that can be satisfied with a digital signature based on the new owners private key.
- lock_ time: Is the Unix epoch time or block number after which the outputs are spendable. This is optional.
Each transaction is broadcast in a serialized byte format called raw format. It is then hashed twice (SHA256(SHA256())) to create its transaction ID - TXID - which, as you already know, is used to create the Merkle tree.
Transactions, being the basic building block of a blockchain, are an example of this:
- First, an understanding of the UTXO accounting model is necessary.
- Second, to understand the ownable part of the data on a blockchain one needs to understand the basic principles of public-key cryptography: private keys, public keys, addresses, and digital signatures.
- Each transaction input includes a signature that authorizes spending, and each newly created output includes information about what a signature needs to look like in order to authorize its spending.
- Lastly, the overall structure of the blockchain needs to be understood.
Summary - Blockchain as a Data Structure
The blockchain in itself is a data structure that stores transactions. It is similar to a linked list in that the data is split into containers - the blocks. Each block is connected with its predecessor with a cryptographically secured reference. This makes the data structure tamper-evident, changes to old blocks are easy to detect and dismissed.
Public blockchains come with powerful features that were not achievable before. It is impossible to change information after the fact. The information is immutable and highly secure. This is why there is value in blockchain. It is an immutable ledger that stores data reliably in a trustless environment. That is why blockchain is perfect for supporting digital money.
A block consists of a header, and the transactions contained. Inside the block, a Merkle tree is used to create a 256 bit summary of all transactions, the Merkle root, which is included in the block header.
A transaction is a message to the network about what unspent transaction outputs (UTXOs) are being spent in a transaction and which new UTXOs are being created.